
Transcription & orthography toolset
This toolset is a loose conglomeration of applications aiming to help you handle various character encodings, orthographies, transcriptions and transliterations you might encounter when working with Uralic languages and other languages of Europe and Northern Asia that use variants of the Latin or Cyrillic alphabet.
User manual and documentation
 |
The user manual and documentation gives a detailed overview of the functionality of the individual tools published here, and gives the sources used to create models for individual languages. It also includes an overview map of the Cyrillic keyboard layout. If you wish to contribute to this toolset and want to help us create resources for additional languages, you will find instructions on the information we need to expand this toolset in the manual. Open manual |
Keyboard layouts
 |
This keyboard layout should cover all Cyrillic orthographies currently in official usage, and a number of archaic ones. It is based on Latin QWERTY-layouts, i.e. the Cyrillic letter “р” /r/ is placed where the letter “r” is placed on QWERTY-layouts used for the Latin alphabet. As there is no 1:1 relationship between letters of the Latin and Cyrillic alphabet, these correspondences are not always perfect. Punctuation marks are arranged as they are on the Finnish/Swedish and Estonian keyboard layouts. Cyrillic Keyboard Layout (Windows) Installation instructions |
Universal diactric helper
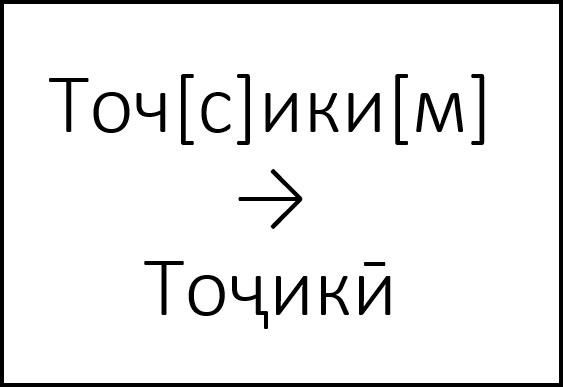 |
The Universal diacritic helper lets you add diacritic markings to Cyrillic and Latin characters, and lets you create non-standard variants of letters. Using this tool, you can create texts in a wide number of orthographies, even if you only have access to a “basic” Latin or Cyrillic keyboard layout. The application uses so-called modifiers, which users should place in square brackets after letters they intend to modify. For example, [a] adds an accent to a letter, [m] a macron: y[a] → ý, a[m] → ā Go to universal diactritic helper |
Transcription and transliteration
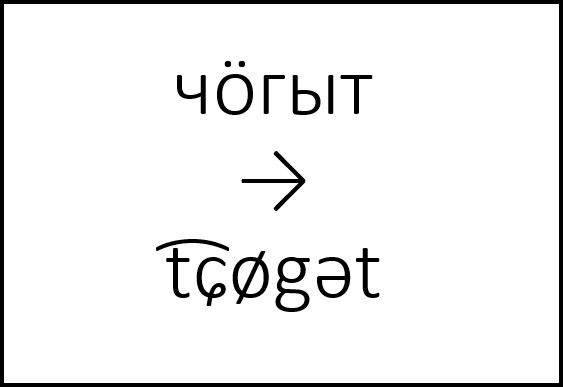 |
These tools transcribe and transliterate from a wide range of writing systems used for the respective language: standard modern Cyrillic orthography, standard modern Latin orthography (if it exists), UPA/Finno-Ugric Transcription, IPA, ISO 9, archaic orthographies. It is currently available for Mari (also Hill Mari), Udmurt, Komi (also Komi-Permyak), Erzya, Moksha, (Northern) Mansi, Tatar, Bashkir, Chuvash, and Russian. Go to transcription and transliteration tool |
Language-specific diacritic helpers
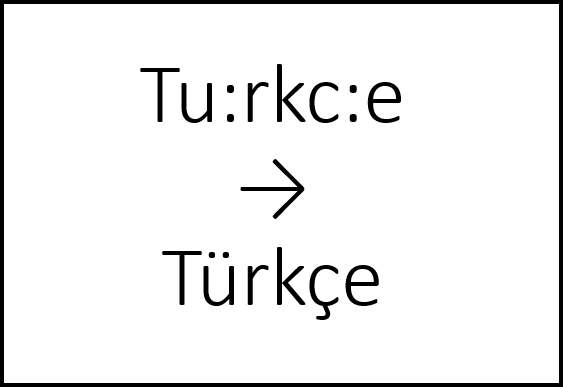 |
This rudimentary tool is available for almost a hundred languages. It gives users an overview of what non-standard (Latin or Cyrillic) characters are in use in the language’s modern literary language, and provides users with a list of shortcuts they can use to access the special characters used in the language at hand. For example, for Turkish, the following transformations are carried out: c: → ç, g: → ğ, i: → ı, o: → ö, s: → ş, u: → ü, a- → â, i- → î, u- → û. The tool is currently available for the following languages: Latin-based orthographies Albanian, Azeri, Basque, Breton, Catalan, Crimean Tatar, Croatian, Czech, Danish, Estonian, Faroese, Finnish, French, Frisian, Fuyu Kyrgyz, Gagauz, German, Hungarian, Icelandic, Inari Saami, Ingrian, Irish, Italian, Karelian, Kven, Latvian, Lithuanian, Livonian, Lule Saami, Maltese, Manx, North Saami, Norwegian, Polish, Portuguese, Romanian, Scottish Gaelic, Skolt Saami, Slovak, Slovene, Sorbian, South Saami, Spanish, Swedish, Turkish, Turkmen, Veps, Võru, Welsh Cyrillic-based orthographies Abaza, Abkhaz, Adyghe, Aghul, Altai, Avar, Azeri, Belarusian, Buryat, Chechen, Chukchi, Dargwa, Dolgan, Dungan, Enets, Even, Evenki, Ingush, Itelmen, Kabardian, Kalmyk, Karachay-Balkar, Kazakh, Ket, Khakas, Khanty, Kildin Saami, Kyrgyz, Lak, Lezgian, Macedonian, Mansi, Mongolian, Nenets, Nganasan, Ossetian, Rutul, Sakha, Selkup, Serbian, Shor, Tabasaran, Tajik, Tat, Tofa, Tsakhur, Tuvan, Ukrainian, Yukaghir Go to diacritic helpers |
Source code
 |
The source code for these tools is published under the Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) license. This means it can be used and reproduced free of charge for non-profit purposes, contingent on attribution. Download source code |
Contact Us
Project Coordination
Prof. Dr. Rogier Blokland
Engelska parken
Thunbergsv. 3 L
751 26 Uppsala
Sweden
Organizational Assistant
Dr. phil. Maximilian Murmann (LMU Munich)
Technical Administration
Dr. tech. Dr. phil. Jeremy Bradley (University of Vienna)
Webmaster
Tobias Weber, M.A. (LMU Munich)